
新网站上线,怎样让搜索引擎收录网站?
当新网站上线后,如果搜索引擎(如百度、Google)迟迟不收录,意味着网站无法通过搜索引擎获取流量。那么,如何让搜索引擎更快地发现并收录你的网站?本文将从技术优化、内容优化、外部推广等多个维度,详细解析新网站收录的策略。
一、搜索引擎收录的基本原理
搜索引擎(如Google、百度)收录一个网站,通常经历以下几个步骤:
发现(Discovery):搜索引擎的爬虫(Spider)通过链接、提交网址等方式发现新站。
抓取(Crawling):爬虫访问网站并下载网页内容。
索引(Indexing):搜索引擎将抓取的内容存入索引数据库,并进行分析分类。
展示(Ranking):当用户搜索相关关键词时,索引库中的页面会被匹配并展示在搜索结果中。
要加快收录速度,就要优化发现、抓取、索引这三个环节。
二、让搜索引擎快速收录网站的有效方法
1. 向搜索引擎主动提交网站
等待搜索引擎主动发现网站可能需要数周甚至更长时间,建议通过搜索引擎站长工具主动提交网站:
百度站长工具:https://ziyuan.baidu.com/
Google Search Console:https://search.google.com/search-console
提交方法:
注册并验证网站(添加HTML文件、DNS验证等)。
提交网站地图(sitemap.xml):
生成
/sitemap.xml文件,包含网站所有重要页面。在站长工具后台提交,如
https://www.example.com/sitemap.xml。主动提交URL:
百度站长工具的“普通收录”或“快速收录”。
Google Search Console的“URL检查”工具,点击“请求收录”。
2. 优化网站结构,提升爬虫抓取效率
确保网站具备清晰的链接结构:
主页 → 栏目页 → 文章页,层级不要超过3层。
内部链接合理分布,保证爬虫可以顺畅访问所有页面。
使用标准URL格式,避免重复内容:
确保网址统一,如:
https://example.com/page/,而不是https://example.com/page/index.html。使用
canonical标签,避免重复内容影响收录。
3. 确保robots.txt允许爬虫抓取
有些网站因robots.txt设置错误,导致搜索引擎无法抓取,检查是否有如下内容:

确保robots.txt文件允许搜索引擎访问,并提供sitemap.xml路径。
4. 提供高质量原创内容,提升索引概率
发布原创、有价值的内容:
文章字数建议800字以上,避免过于简短。
使用清晰的标题(H1)、小标题(H2、H3),提升阅读体验。
避免大量采集、重复内容:
搜索引擎对原创内容友好,如果大量使用采集或拼接内容,可能导致不收录。
定期更新:
新站初期建议每天更新1-2篇内容,保证爬虫频繁访问。
5. 增加外部链接,提高网站权重
新网站刚上线时,权重较低,爬虫发现的概率较小。可以通过外部链接引导爬虫加快收录:
在高权重平台发布网站链接:
论坛(如知乎、百度贴吧)、博客(如CSDN)、社交媒体(微博、小红书)。
交换友情链接:
找同类型网站交换友情链接,提高信任度。
在知名网站投稿:
投稿至行业门户、新闻站点,带动流量并提高权重。
6. 使用百度/Google推送工具(加快收录)
如果希望更快速地被百度或Google收录,可以使用API推送:
百度:使用“主动推送(API)”工具,自动提交新页面,缩短收录时间。
Google:使用Google Indexing API,加快动态页面收录速度。
7. 提高网站加载速度,优化用户体验
搜索引擎倾向于收录加载速度快、用户体验好的网站:
开启CDN,提高全球访问速度(如Cloudflare、百度云CDN)。
优化图片,使用WebP格式,减少图片体积。
启用Gzip压缩,减少页面加载时间。
三、如何判断网站是否被收录?
1. 使用搜索指令查询
在百度或Google搜索:
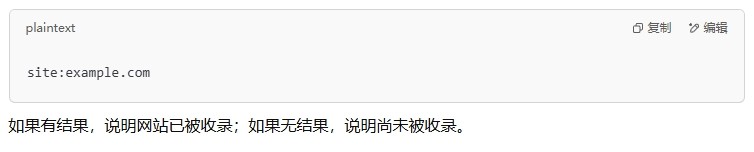
2. 通过站长工具查看
在百度站长工具或Google Search Console中,查看索引状态和抓取情况。
四、新站收录常见问题及解决方案
1. 网站很久不收录,怎么办?
✅ 检查robots.txt是否允许爬虫抓取。
✅ 查看站长工具日志,确保爬虫正常访问。
✅ 提高内容质量,避免采集和拼接内容。
✅ 增加外链,提高爬虫发现的概率。
✅ 使用百度API推送,加快收录速度。
2. 只收录首页,内页不收录?
✅ 确保内页有良好的内部链接结构。
✅ 避免JS动态加载内容,爬虫无法解析JS渲染的内容。
✅ 主动提交sitemap.xml,并使用API推送。
3. 网站内容收录后排名不佳?
✅ 优化标题和描述,包含核心关键词。
✅ 提升网站打开速度,减少跳出率。
✅ 定期更新高质量内容,增加用户粘性。